Merkelized Map¶
Merkelized map is a version of a typed map that supports compact proofs of existence for its elements using Merkle trees. Merkelized maps in MerkleDB are designed as binary Merkle Patricia trees.
A binary Merkle Patricia tree (MPT for short; the Patricia tree part is also known as trie or prefix tree) is a trie in which edges are labelled by bit sequences. MerkleDB uses tries in which all paths to trie leaves have fixed length – 32 bytes or 256 bits. Each node of the trie stores a hash digest; digests are computed recursively from leaves to the tree root. Thus, the root hash of the tree commits to all key–value pairs in the tree.
Note
Unlike some map hashing techniques used in other blockchains (e.g., AVL trees), Merkle Patricia trees and their root hashes are not dependent on the order in which elements are added or removed from the map, only on the map contents. Also, small number of children for tree nodes simplifies some algorithms.
ProofMapIndex Insights¶
Since paths in an MPT need to have fixed length, keys in the original map
need to be transformed to the corresponding format.
ProofMapIndex provides two ways to accomplish this:
- Hashed transform is used by default and works with any serializable key type. In this case, the transform is to hash the key serialization with SHA-256 and use the output as an MPT path. Because of cryptographic properties of SHA-256, the transform is resistant to collisions and pre-image attacks.
- Raw transform means that the original key serialization is used. This transform is advised only for key types that always serialize to 32 bytes and have uniform distribution over the key space. (The latter is to limit the MPT depth.) Types that can be used with the raw transform include 32-byte outputs of a cryptographic hash function and Ed25519 public keys.
Because the key transform may be irreversible, ProofMapIndex stores both original
map keys and paths in the MPT split with a prefix tag. Iteration and retrieval
are always performed on the original keys.
Redefining Tree Root¶
Because of implementation reasons, nodes in an MPT used in MerkleDB can have
0 or 2 children, never 1. This requirement naturally follows for leaves
and intermediate nodes in a generic binary trie; it can only be violated
for the root node (e.g., if all paths in the trie start with 0 bit).
To deal with this, MerkleDB redefines the tree root as the only child node of a “true” root node if the latter has a single child. Thus, in the following description the tree root always has 0 or 2 children, and there is a special case if the MPT has a single leaf node.
Computing Map Hash¶
As with lists, computing hash of a map consists of two steps:
- Computing the root hash of the MPT
- Computing the map hash using the root hash.
The second part is easy; given the root_hash of the MPT, the hash
of the corresponding map is
map_hash = hash( HashTag::MapNode || root_hash ),
where HashTag::MapNode = 3 is the domain separation tag for map objects,
hash() is the SHA-256 function, || is byte concatenation.
(Here and elsewhere, tags are serialized as a single byte.)
How root_hash computed, depends on the number of entries in the map.
Empty Map¶
Root hash of an empty map is defined as 32 zero bytes.
Map With a Single Element¶
Root hash for a map with a single entry is computed as follows:
root_hash = hash(
HashTag::MapBranchNode ||
key_path ||
value_hash
);
value_hash = hash(HashTag::Blob || value),
where
HashTag::MapBranchNode = 4is the domain separation tag for MPT nodes.key_pathis the 256-bit MPT path obtained by transforming the entry key.value_hashis the domain-separated hash of the entry value with tagHashTag::Blob = 0.
key_path serialization follows the generic format:
LEB128(bit_length) || bytes,
where
- LEB128 is a compact serialization format for unsigned integers
bit_lengthis the number of bits in the path (i.e., 256 in this case)bytesis the path serialized as the minimum necessary number of bytes, with zero padding at the end if necessary. (In this case,byteshas length 32 and contains no padding.)
Map With More Than One Element¶
As defined above, in a map with 2 or more elements the MPT root always has two children. The root hash is defined as
root_hash = hash(
HashTag::MapBranchNode ||
left_path || right_path
left_hash || right_hash
).
Here
left_pathandright_pathare serialized paths to the child nodes. The same serialization format is used as in the previous case.left_hashandright_hashare 32-byte hashes associated with the child nodes.
Hashes associated with child nodes are computed recursively:
- If a node has 2 children, its hash is computed in the same way as for the root
- If a node is a leaf, its hash is
hash(HashTag::Blob || value), wherevalueis binary serialization of the value associated with the node.
MPT Proofs¶
Proofs allow to efficiently and compactly verify that one or more values are associated with specific keys in a Merkelized map, or that a certain key has no associated value.
One could think of proofs as of MPT pruning. That is, a proof is produced by “collapsing” some intermediate nodes in the MPT. Another point of view – from the light client perspective – is that a proof is essentially a limited view of a map, for which the MPT is constructed. This view allows to calculate the map hash and proves that certain elements are contained in the map.
Proof Example¶
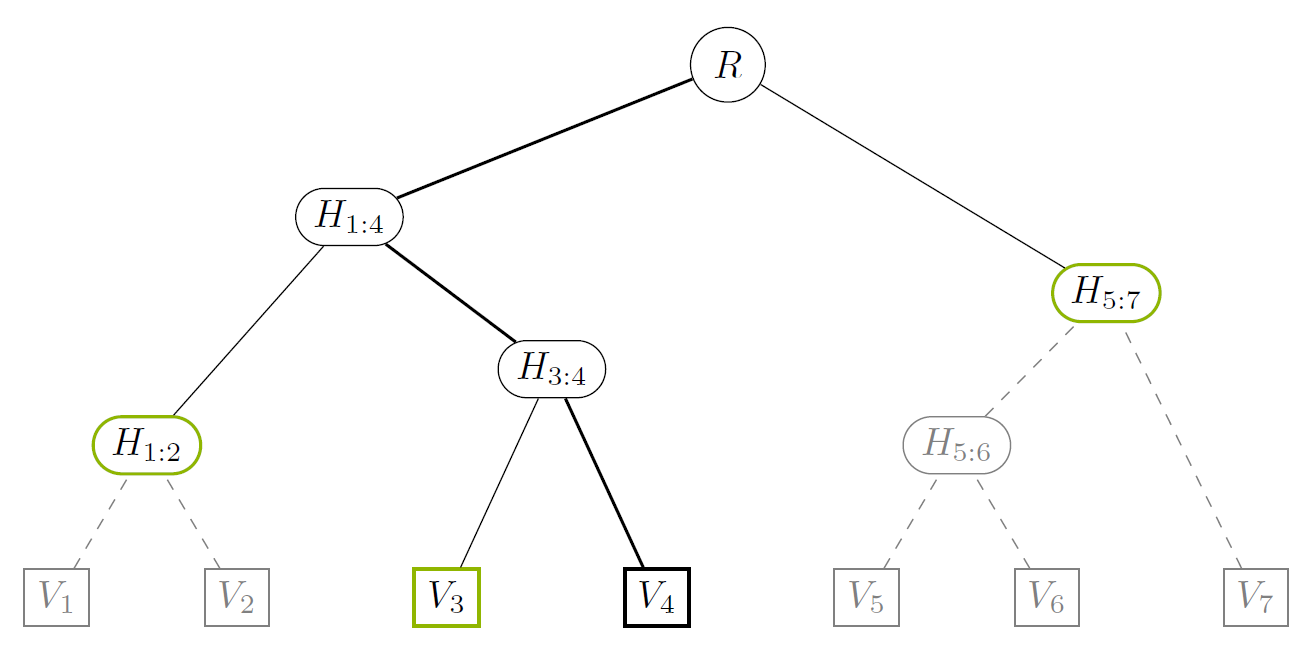
This figure illustrates a map proof for the 4th element in a map with 7 elements. Intermediate MPT nodes included in the proof are highlighted. Pruned nodes are faded and have dashed contours.
Format¶
The proofs returned by the Exonum storage engine are non-recursive, thus minimizing overhead (i.e., heap allocations) and allowing to use them in environments not allowing recursive data types. A proof consists of three principal parts:
- Entries proven to exist in the map (i.e., values together with respective keys)
- Keys proven to not exist in the map
- Intermediate MPT nodes that together with entries allow to restore map hash. Intermediate nodes are identified by the complete path to a node from the true MPT root.
Protobuf spec
message MapProof {
repeated OptionalEntry entries = 1;
repeated MapProofEntry proof = 2;
}
// Key with corresponding value and empty value if key is missing.
message OptionalEntry {
bytes key = 1;
oneof maybe_value {
bytes value = 2;
google.protobuf.Empty no_value = 3;
}
}
// Proof path and corresponding hash value.
message MapProofEntry {
// Path to the node, expressed with the minimum necessary number of bytes.
// Bits within each byte are indexed from the least significant to
// the most significant.
// The last byte may be padded with zeros if necessary.
bytes path = 1;
// Hash associated with the node.
exonum.crypto.Hash hash = 2;
// Number of zero bit padding at the end of the path.
// Must be in the `0..8` interval.
uint32 path_padding = 3;
}
TypeScript spec of JSON serialization
interface MapProof<K, V> {
proof: ProofEntry[],
entries: ({ missing: K } | { key: K, value: V })[],
}
interface ProofEntry {
path: string, // binary string, e.g., '00101'
hash: string, // 64 hex digits
}
Proof Verification¶
While validating the proof, a client restores root_hash and
computes the map hash. Depending on the use case, the map hash
can be compared to a trusted reference or participate in further aggregation.
For keys asserted to be missing from the map, the client checks that a key is impossible to fit into MPT. That is, after converting a missing key to an MPT path and trying to traverse this path from the root node, the traversal ends in the middle of an edge.
Computing root_hash can be done by restoring the pruned MPT
from the information in the proof and computing the hash of its
root node as per Computing Map Hash section.
MerkleDB implementation and reference light clients actually utilize
a more efficient algorithm based on tree contours. This algorithm
is described in the MerkleDB technical docs.